주소로 고객 검색 서비스 구축하기(feat. Elastic Search v 8.6.2, MacOS) - 3.5탄 (feat. Polars)
안녕하세요. 클스 입니다.
Polars 란
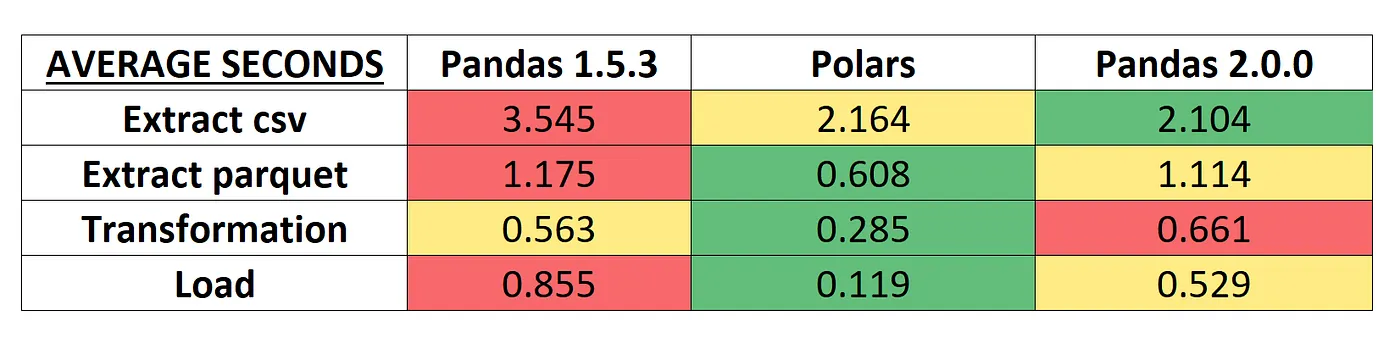
Rust로 개발된 data frame 처리하는 라이브러리 입니다. pandas 보다 속도가 빠르다고 하네요~
Pandas로 현재는 1.5.3 버전이지만 2.0에서는 성능이 많이 개선되는 것 같습니다.
제가 사용하기에는 함수명이 Polars가 더 친숙합니다. 그래서 앞으로 업무에는 Polars를 많이 사용해보려고
합니다.
polars : https://pola-rs.github.io/polars-book/user-guide/introduction.html
https://towardsdatascience.com/pandas-vs-polars-a-syntax-and-speed-comparison-5aa54e27497e
https://levelup.gitconnected.com/pandas-vs-polars-vs-pandas-2-0-fight-7398055372fb
걸리는 시간뿐아니라, 메모리 사용량, CPU 부하등도 같이 해줬네요~
https://pythonspeed.com/articles/polars-memory-pandas/
다만, Polars는 아직 csv, excel 등을 읽을때, 한글 인코딩 처리라던지 몇가지 잘안되는 부분이 있는것 같습니다.
앞서 csv를 대량으로 elastic search에 업로드할 때 pandas로 개발했지만, 이번에는 Polars로 개발한 코드 입니다.
'''
batch size 로 csv를 읽어서 elastic search에 insert 함
num_of_threads 는 CPU의 thread 갯수에서 절반 정도 해야 다른 작업도 합니다.
'''
import polars as pl
from elasticsearch import Elasticsearch
from elasticsearch import helpers
from elasticsearch.helpers import bulk
import urllib3
import time
import json
import os
import re
# inore ssl warning
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
# This mac 6 core 12 thread so print 12num_of_threads:int = int(pl.threadpool_size()/2)
print(f'Polars Threads Count : {pl.threadpool_size()} totals {num_of_threads} using')
# 기존 파일을 UTF8로 변환 함.
csv_file = r'~/Downloads/6300000_CSV/6300000_대전광역시_07_24_04_P_일반음식점_UTF8.csv'
# batch reader
start = time.time()
filename = os.path.splitext(os.path.basename(csv_file))[0]
reg_pattern = re.compile(r'[ㄱ-ㅣ가-힣]+')
reg_results = re.findall(reg_pattern, csv_file)
index_name = "_".join(reg_results) # index name은 파일명에서 가져온다.
if index_name == '':
print('index_name is empty');
exit()
es_client = Elasticsearch("https://localhost:9200", basic_auth=("elastic", "your pwd"), ca_certs=False, verify_certs=False)
reader = pl.read_csv_batched(csv_file, encoding='utf8-lossy', batch_size=10000, n_threads=num_of_threads)
# 숫자는 batch_size * n 이다. 여기서 1은 배치를 1회만 돌려서 가져오라는 것
batches = reader.next_batches(1)
while batches:
documents = batches[0].to_dicts()
actions = [
{
"_index": index_name,
"_id" : f'{document["개방자치단체코드"]}{document["관리번호"]}',
"_source": document
}
for document in documents
]
bulk(es_client, actions)
batches = reader.next_batches(1)
end = time.time()
print(f"1 >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> {end - start}")
배치 사이즈별로 전체 INSERT에 거리는 시간을 재봤습니다.
# 96.64808893203735 batch_size=10 - bad
# 22.09470009803772 batch_size=1000 - good
# 23.36481308937072 batch_size=5000 - default
# 21.92650175094604 batch_size=10000 - good
Pandas 처러 nan 을 nan으로 처리해서 ''로 치환하고 이런 작업은 안해도 돼서, usecols은 사용하지 않았습니다.
pandas 1000 배치 사이즈로 17.13812804222107 초 걸렸네요~ 파일은 동일 합니다. Pandas가 빠른듯 보이지만 컬럼을 절반만 사용했습니다.
제 Mac에서 돌리니 성능 비교는 어렵네요~
다음에는 Polars로 데이터 처리하는 방법을 한번 써보겠습니다.
이번에 Polars를 보면서 이제 Python이 데이터 분석/처리에 절대 강자가 아닐 수 도 있다는 생각이 듭니다.
Rust로 개발됐기 때문에 당연히 Rust에서 빠르게, 더 적은 메모리로 돌아 갑니다.
Elastic Search도 이제 Rust로 개발됐으면 하는 바램입니다.
이만~
라벨: ElasticSearch, Polars